 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnconstrained Multi-view Human Pose Estimation with Algebraic Priors
Apr 27, 2026Recovering 3D human pose from multi-view imagery typically relies on precise camera calibration, which is often unavailable in real-world scenarios, thereby severely limiting the applicability of existing methods. To overcome this challenge, we propose an unconstrained framework that synergizes deep neural networks, algebraic priors, and temporal dynamics for uncalibrated multi-view human pose estimation. First, we introduce the Triangulation with Transformer Regressor (TTR), which reformulates classical triangulation into a data-driven token fusion process to bypass the dependency on explicit camera parameters. Second, to explicitly embed the inherent algebraic relations of the multi-view variety into the learning process, we propose the Gröbner basis Corrector (GC). This pioneering loss formulation enforces constraints derived from the multi-view variety to ensure the neural predictions strictly adhere to the laws of projective geometry. Finally, we devise the Temporal Equivariant Rectifier (TER), which exploits the equivariance property of human motion to impose temporal coherence and structural consistency, effectively mitigating scale ambiguity in uncalibrated settings. Extensive evaluations on standard benchmarks demonstrate that our framework establishes a new state-of-the-art for uncalibrated multi-view human pose estimation. Notably, our approach significantly closes the performance gap between calibration-free methods and fully calibrated oracles.
Monocular Depth Estimation via Neural Network with Learnable Algebraic Group and Ring Structures
Apr 27, 2026Monocular depth estimation (MDE) has witnessed remarkable progress driven by Convolutional Neural Networks and transformer-based architectures. However, these approaches typically treat the problem as a generic image-to-image regression on Euclidean grids, thereby overlooking the intrinsic algebraic and geometric structures induced by perspective projection. To address this limitation, we propose LAGRNet, a novel framework that fundamentally grounds MDE in algebraic geometry by explicitly embedding learnable group, ring, and sheaf structures into the deep learning pipeline. Modeling feature maps as sections of a sheaf over an approximated image manifold, our method first establishes a Group-defined Feature Manifold (GFM) parameterized by a learned algebraic group action to enforce projective equivariance and robustness against view changes. To facilitate algebraically consistent cross-scale interactions, we subsequently introduce a Ring Convolution Layer (RCL) that formulates feature fusion as a graded ring homomorphism. Furthermore, to ensure global topological consistency, a Sheaf-based Module (SM) aggregates local depth cues via Čech nerve on the image topology. Extensive zero-shot evaluations across the KITTI, NYU-Depth V2, and ETH3D benchmarks demonstrate that LAGRNet significantly outperforms state-of-the-art methods in both accuracy and generalization capabilities.
Fourier Boundary Features Network with Wider Catchers for Glass Segmentation
May 15, 2024



Glass largely blurs the boundary between the real world and the reflection. The special transmittance and reflectance quality have confused the semantic tasks related to machine vision. Therefore, how to clear the boundary built by glass, and avoid over-capturing features as false positive information in deep structure, matters for constraining the segmentation of reflection surface and penetrating glass. We proposed the Fourier Boundary Features Network with Wider Catchers (FBWC), which might be the first attempt to utilize sufficiently wide horizontal shallow branches without vertical deepening for guiding the fine granularity segmentation boundary through primary glass semantic information. Specifically, we designed the Wider Coarse-Catchers (WCC) for anchoring large area segmentation and reducing excessive extraction from a structural perspective. We embed fine-grained features by Cross Transpose Attention (CTA), which is introduced to avoid the incomplete area within the boundary caused by reflection noise. For excavating glass features and balancing high-low layers context, a learnable Fourier Convolution Controller (FCC) is proposed to regulate information integration robustly. The proposed method has been validated on three different public glass segmentation datasets. Experimental results reveal that the proposed method yields better segmentation performance compared with the state-of-the-art (SOTA) methods in glass image segmentation.
AVM-SLAM: Semantic Visual SLAM with Multi-Sensor Fusion in a Bird's Eye View for Automated Valet Parking
Sep 15, 2023Automated Valet Parking (AVP) requires precise localization in challenging garage conditions, including poor lighting, sparse textures, repetitive structures, dynamic scenes, and the absence of Global Positioning System (GPS) signals, which often pose problems for conventional localization methods. To address these adversities, we present AVM-SLAM, a semantic visual SLAM framework with multi-sensor fusion in a Bird's Eye View (BEV). Our framework integrates four fisheye cameras, four wheel encoders, and an Inertial Measurement Unit (IMU). The fisheye cameras form an Around View Monitor (AVM) subsystem, generating BEV images. Convolutional Neural Networks (CNNs) extract semantic features from these images, aiding in mapping and localization tasks. These semantic features provide long-term stability and perspective invariance, effectively mitigating environmental challenges. Additionally, data fusion from wheel encoders and IMU enhances system robustness by improving motion estimation and reducing drift. To validate AVM-SLAM's efficacy and robustness, we provide a large-scale, high-resolution underground garage dataset, available at https://github.com/yale-cv/avm-slam. This dataset enables researchers to further explore and assess AVM-SLAM in similar environments.
Real-time Streaming Perception System for Autonomous Driving
Jul 30, 2021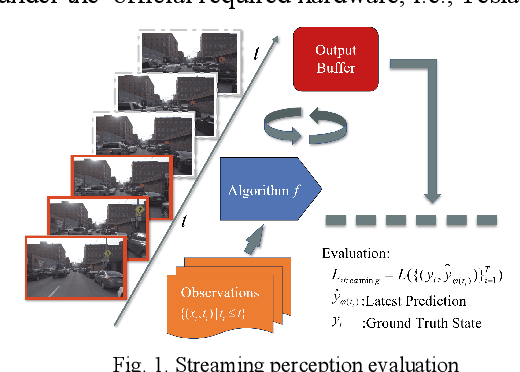
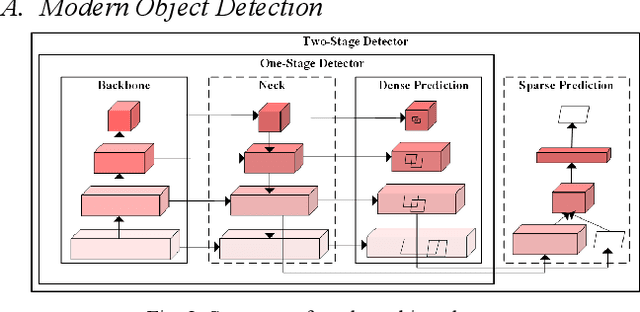
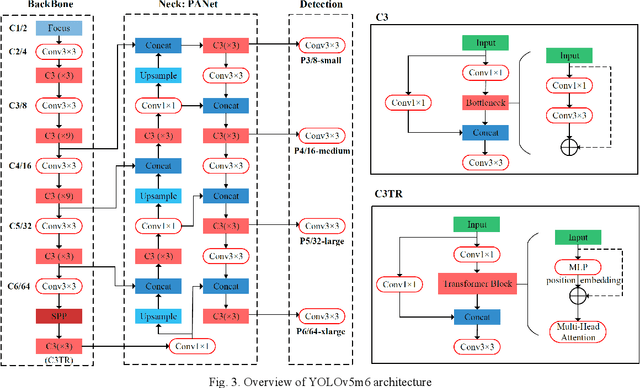
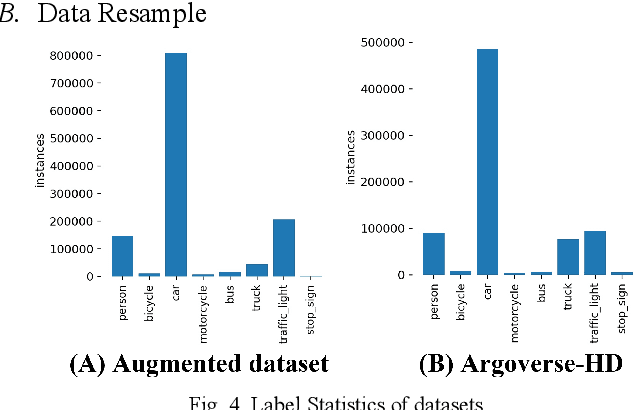
Nowadays, plenty of deep learning technologies are being applied to all aspects of autonomous driving with promising results. Among them, object detection is the key to improve the ability of an autonomous agent to perceive its environment so that it can (re)act. However, previous vision-based object detectors cannot achieve satisfactory performance under real-time driving scenarios. To remedy this, we present the real-time steaming perception system in this paper, which is also the 2nd Place solution of Streaming Perception Challenge (Workshop on Autonomous Driving at CVPR 2021) for the detection-only track. Unlike traditional object detection challenges, which focus mainly on the absolute performance, streaming perception task requires achieving a balance of accuracy and latency, which is crucial for real-time autonomous driving. We adopt YOLOv5 as our basic framework, data augmentation, Bag-of-Freebies, and Transformer are adopted to improve streaming object detection performance with negligible extra inference cost. On the Argoverse-HD test set, our method achieves 33.2 streaming AP (34.6 streaming AP verified by the organizer) under the required hardware. Its performance significantly surpasses the fixed baseline of 13.6 (host team), demonstrating the potentiality of application.